Lakehouse Pipeline Architecture
A breakdown of the medallion-layered ETL pipeline using AWS Glue, S3, and Athena.
Medallion Architecture Overview
The pipeline follows the Bronze → Silver → Gold design pattern to clean, enrich, and structure event data for AI workloads:
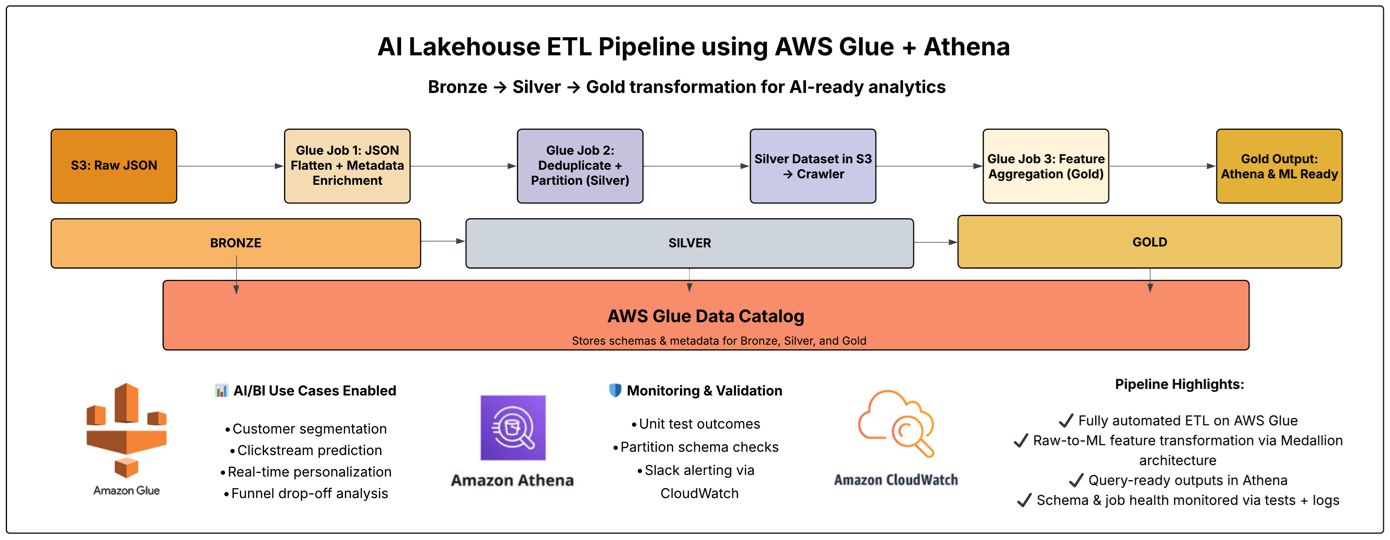
Diagram: JSON events flow through Bronze → Silver → Gold, becoming AI-ready at each stage.
ETL Jobs with AWS Glue (PySpark)
Each layer is handled by a dedicated AWS Glue job:
- bronze_job_parquet.py → JSON → Parquet (with schema enrichment)
- silver_job_parquet.py → Deduplicates, filters nulls, adds partitioning
- gold_user_features.py → Aggregates user-level features for ML
Jobs run on-demand with Glue 5.0 (Spark 3.5) using 2 DPUs, with execution time under 2 minutes.
S3 Storage Layering
All transformed data is stored in Amazon S3 in Parquet format:
s3://ai-lakehouse-project/raw/— raw JSONs3://ai-lakehouse-project/bronze/user_events_parquet/s3://ai-lakehouse-project/silver/user_events/(partitioned)s3://ai-lakehouse-project/gold/user_features/
Partitioning is applied on Silver and Gold layers for optimized Athena querying.
Metadata & Query Layer
Each layer is registered via AWS Glue Crawler and made queryable in Athena:
bronze_user_events_parquetsilver_user_eventsgold_user_features
Sample Athena queries show sub-second response times with partition pruning enabled for Silver and Gold layers.
Data Quality Layer
A dedicated AWS Glue job runs validations on the Silver Layer before ML or analytics. It checks for nulls, duplicates, and schema mismatches, writing results to both S3 and Markdown.
- Null value checks for key columns
- Duplicate detection (e.g.
user_id+event_timestamp) - Schema conformity (column types + presence)
- JSON and Markdown reports stored in
s3://ai-lakehouse-project/reports/
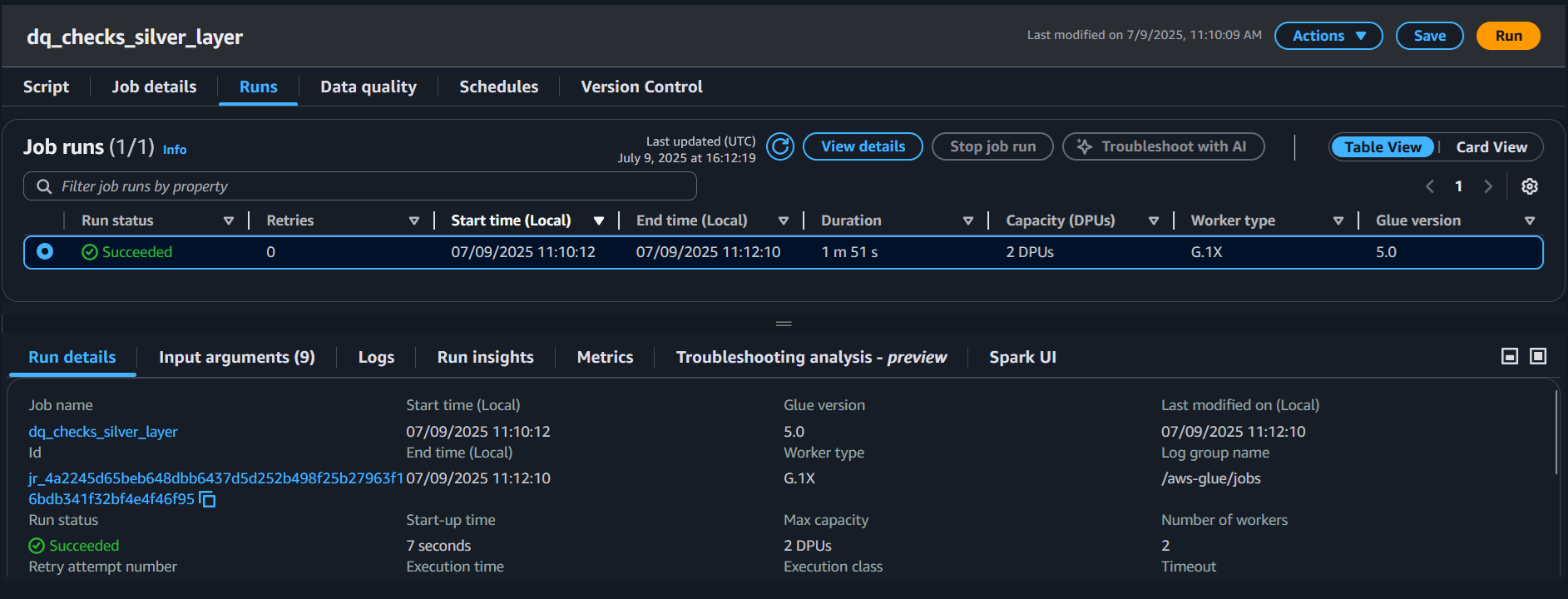
Glue job verifying Silver layer integrity before downstream use.
Example Gold Table Schema
user_id STRING
last_event_timestamp TIMESTAMP
click_count INT
purchase_count INT
last_feature_hash STRINGSchema inferred and cataloged by AWS Glue from partitioned Parquet data.
Sample Athena Query
SELECT user_id, click_count, purchase_count,
last_event_type, last_event_timestamp
FROM ai_lakehouse_db.gold_user_features
ORDER BY last_event_timestamp DESC
LIMIT 10;This query fetches recent user activity summaries directly from the Gold layer using partition-aware scanning.